

Dust is a rewrite of du (in rust obviously) that visualizes your directory tree and what percentage each file takes up. But it only prints as many files fit in your terminal height, so you see only the largest files. It’s been a better experience that du, which isn’t always easy to navigate to find big files (or atleast I’m not good at it.)
Anyway, found a log file at .local/state/nvim/log that was 70gb. I deleted it. Hope it doesn’t bite me. Been pushing around 95% of disk space for a while so this was a huge win 👍
You must log in or register to comment.
I think something might be wrong with your Neovim if it aggregated 70 gigs of log files.
don’t worry, they’ve just been using neovim for 700 years, it’ll be alright
Sure, that’s also a possibility. I’d be interested in their time machine though.
So I found out that qbittorrent generates errors in a log whenever it tries to write to a disk that is full…
Everytime my disk was full I would clear out some old torrents, then all the pending log entries would write and the disk would be full again. The log was well over 50gb by the time I figured out that i’m an idiot. Hooray for having dedicated machines.
That’s not entirely your fault; that’s pathological on the part of the program.
I once did something even dumber. When I was new to Linux and the CLI, I added a recursive line to my shell config that would add it self to the shell config. So I pretty much had exponential growth of my shell config and my shell would take ~20 seconds to start up before I found the broken code snippet.
If you have ideas please let me know. I’m preparing to hop distros so I’m very tempted to ignore the problem, blame the old distro, and hope it doesn’t happen again :)
I would have to look at the log file. Some plugin probably has an issue and writes massive amounts of data to the log every time you use Neovim. Monitor the growth of the log file and contact me via DM if it goes crazy again, I’m gonna try to figure out what’s going on.
ncdu is the best utility for this type of thing. I use it all the time.
I install ncdu on any machine I set up, because installing it when it’s needed may be tricky
Try dua. It’s like ncdu but uses multiple threads so it’s a lot faster., especially on SSDs.
deleted by creator
Why does it suck that it’s written in Go?
deleted by creator
So you hate a language just because who it’s associated with. That’s dumb. Go is an awesome language, I used it at work for 2 years.
Garbage collected languages will never not be at least slightly ick
Edit: I did not expect this to be so controversial, especially in regard to go, but I stand by my statement.
absurd take
Counterpoint: I’ve never used Go myself, but I love that Go apps usually seem to be statically-linked executables. I have a few utilities (such as runitor) that I ‘deploy’ to my servers by just copying them into /usr/local/bin using Ansible.
Go is awesome, yet a slight pain in the ass some ways, but you get used to it. I was doing DevOps stuff with it for 3 years. I like it so much more than python.
deleted by creator
Yes, it looks very similar. The guy of ncdu is making a new improved and faster version in Zig.
For great justice?
Came in expecting a story of tragedy, congrats. 🎉
But did he even look at the log file? They don’t get that big when things are running properly, so it was probably warning him about something. Like “Warning: Whatever you do, don’t delete this file. It contains the protocol conversion you will need to interface with the alien computers to prevent their takeover.”
PTSD from the days long ago when X11 error log would fill up the disk when certain applications were used.
Try
ncduas well. No instructions needed, just runncdu /path/to/your/directory.If you want to scan without crossing partitions, run with
-xRemoved by mod
MINI GUIDE TO FREEING UP DISK SPACE (by a datahoarder idiot who runs on 5 gigs free space on 4 TB)
You will find more trash with the combination of 4 tools. Czkawka (duplicates and big files), Dupeguru (logs), VideoDuplicateFinder by 0x90d, and tune2fs.
VDF finds duplicates by multiple frames of a video, and with reversing frames, and you can set similarity % rate and duration of videos. It is the best tool of its kind with nothing to match it, and uses ffmpeg as backend.
There is a certain amount of disk space reserved on partitions for root or privileged processes, but users who create /home partition separately do not need this reserved space there. 5% space is reserved by default, no matter if your disk is 1 TB, 2 TB or 4 TB. To change this, use command
sudo tune2fs -m N(where N is % you want to reserve, can be put to 0% for /home, but NEVER touch root, swap or others, use GParted to check which is which partition).Regular junk cleaning on Linux can be done with BleachBit. Wipe free disk space once in 3-6 months atleast.
On Windows, use PrivaZer instead of BleachBit.
Since all of these are GUI tools (except tune2fs which requires no commandline hackerman knowledge), this guide is targeted towards tech literacy level of users who can atleast replace crack EXEs in pirated games on Windows.
What about the video similarity finding tool built into Czkawka? Is it not as good as VDF?
No, not even a contest. Nothing compares to VDF.
I usually use something like
du -sh * | sort -hr | less, so you don’t need to install anything on your machine.Same, but when it’s real bad sort fails 😅 for some reason my root is always hitting 100%
I usually go for du -hx | sort -h and rely on my terminal scroll back.
dust does more than what this script does, its a whole new tool. I find dust more human readable by default.
Maybe, but I need it one time per year or so. It is not a task for which I want to install a separate tool.
Perfect for your use case, not as much for others. People sharing tools, and all the different ways to solve this type of problem is great for everyone.
Almost the same here. Well,
du -shc *|sort -hrI admin around three hundred linux servers and this is one of my most common tasks - although I use -shc as I like the total too, and don’t bother with less as it’s only the biggest files and dirs that I’m interested in and they show up last, so no need to scrollback.
When managing a lot of servers, the storage requirements when installing extra software is never trivial. (Although our storage does do very clever compression and it might recognise the duplication of the file even across many vm filesystems, I’m never quite sure that works as advertised on small files)
I admin around three hundred linux servers
What do you use for management? Ansible? Puppet? Chef? Something else entirely?
Main tool is Uyuni, but we use Ansible and AWX for building new vms, and adhoc ansible for some changes.
Interesting; I hadn’t heard of Uyuni before. Thanks for the info!
Seems it just runs Salt/Saltstack?
Suse forked Redhat’s Spacewalk just before it turned into Foreman + Katello.
Then worked an absolute crapload on it to turn it into a modern orchestrator. Part of that was to adopt salt as the agent interface, gradually getting rid of the creaking EL traditional client.
To say “it just runs salt” is to rather miss all the other stuff Uyuni does. Full repo and patch management, remote control, config management, builds, ansible playbook support, salt support, and just about everything else you need to manage hundreds of machines. Oh, and it does that for Rocky, RHEL, Alma, Suse, Ubuntu, Debian and probably a bunch more too, by now. Has a very rich webui, a full API and you can do a bunch more from the cli as well. And if your estate gets too big to manage with one machine, there are proxy agents, as many as you want. I only run a couple of hundred vms through it, but there are estates running thousands.
And it’s free and foss.
Honestly, it’s pretty awesome and I’m amazed it’s not more widely known.
Oh that’s pretty nifty, thanks for the comment. Sorry wasn’t trying to minimize the tool, I was simply referring to the orchestration/config management aspect of it when I looked it up real quick.
I used to be responsible for configurations of 40,000 (yes forty thousand) VMs for a large company using puppet and then later using Ansible and that was an interesting challenge. I’ve been out of the configuration management game for a few years now though so I’m pretty out of the loop. Was familiar with spacewalk back in the day too.
I’ll have to check Uyuni out, thanks for sharing!
We’d use
du -xh --max-depth=1|sort -hrdu -xh --max-depth=1|sort -hr
Interesting. Do you often deal with dirs on different filesystems?
Yeah, I was a Linux System Admin/Engineering for MLB/Disney+ for 5 years. When I was an admin, one of our tasks was clearing out filled filesystems on hosts that alerted.
Sounds pretty similar to what I do now - but never needed the -x. Guess that might be quicker when you’re nested somewhere there is a bunch of nfs/smb stuff mounted in.
We’d do it from root (/) and drill down from there, it was usually /var/lib or /var/logs that was filling up, but occasionally someone would upload a 4.5 GB file to their home folder which has a quota of 5 GB.
Using ncdu would have been the best way, but that would require it being installed on about 7 thousand machines.
I’d say head -n25 instead of less since the offending files are probably near the top anyway
Or head instead of less to get the top entries
With sort -hr, the biggest ones are generally at the bottom already, which is often what most people care about.
So like filelight?
I really like ncdu
Yeah I got turned onto ncdu recently and I’ve been installing it on every vm I work on now
check out
dua. I usually use it in interactive most which lets you navigate through the file system with visual representations of total dir/file size.Here is a screenshot randomly found from the github issues
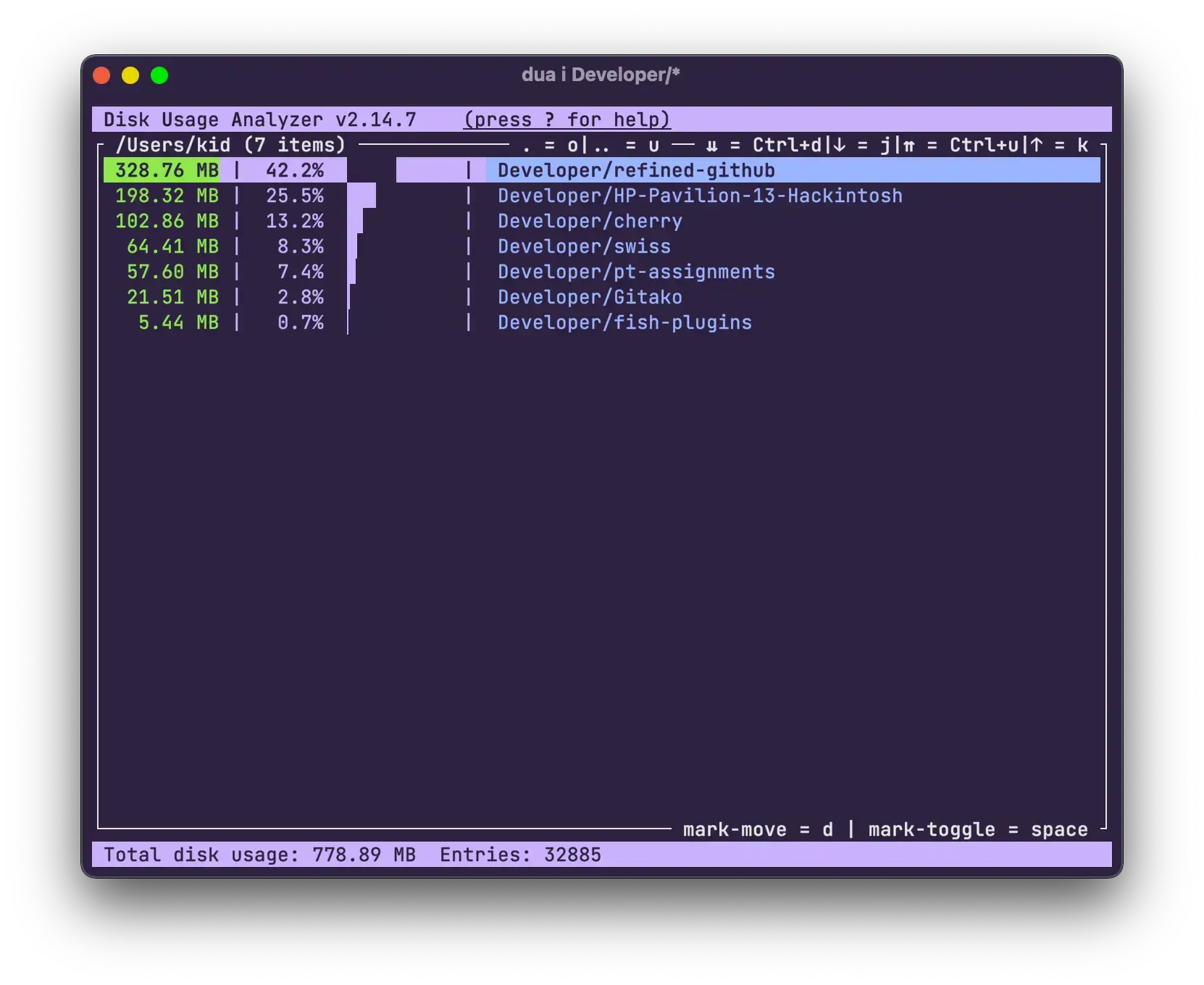
I also recently found this gui program called
k4dirstatburied in the repos. There are a few more modern options but this one blows them all out of the park.Screenshot from the github repo:
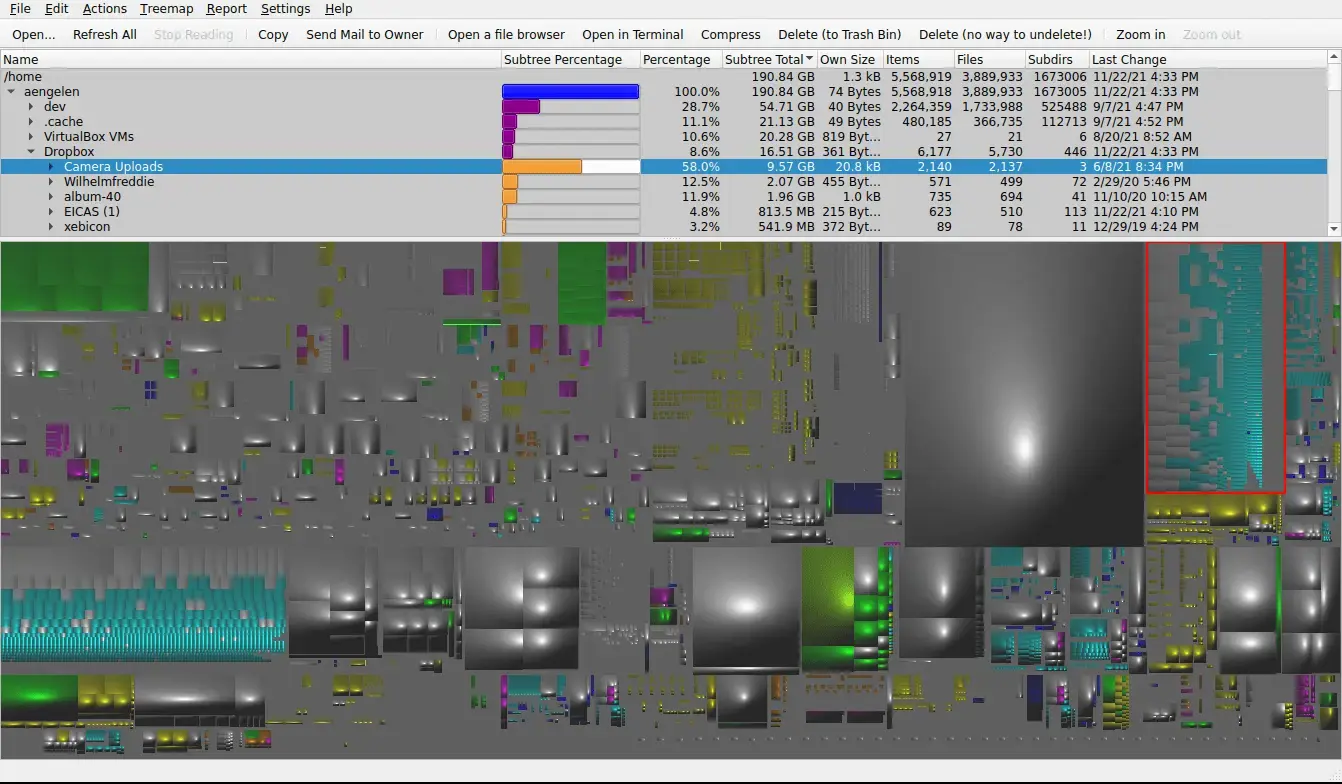
Too bad they used such an ugly configuration for the screenshot… It allows you to modify the visualization to look better and display information differently. Anyway just thought I’d share as the project is old and little known.
thanks for sharing a screenshot of ncdu, should help others discover it
for the visualization itself IMHO Disk Usage Analyzer gives aesthetically pleasing results, not a fan of the UX but it works well enough to identify efficiently large files or directories
A 70gb log file?? Am I misunderstanding something or wouldn’t that be hundreds of millions of lines
I’ve definitely had to handle 30gb plain text files before so I am inclined to believe twice as much should be just as possible
You guys aren’t using
du -sh ./{dir1,dir2} | sort -nh | head?Maybe other tools support this too but one thing I like about xdiskusage is that you can pipe regular du output into it. That means that I can run du on some remote host that doesn’t have anything fancy installed, scp it back to my desktop and analyze it there. I can also pre-process the du output before feeding it into xdiskusage.
I also often work with textual du output directly, just sorting it by size is very often all I need to see.
I miss WinDirStat for seeing where all my hard drive space went. You can spot enormous files and folders full of ISOs at a glance.
For bit-for-bit duplicates (thanks, modern DownThemAll), use fdupes.
If WizTree is available on Linux then I highly recommend it over all other alternatives.
It reads straight from the table and is done within a couple of seconds.
Qdirstat? https://github.com/shundhammer/qdirstat Filelight is also really good https://apps.kde.org/filelight/
Qdirstat will not size its damn rectangles properly in Mint. Massive empty voids for no discernible reason.
Filelight is just objectively worse than a grid-based overview.
Filelight on linux
Squirreldisk on windows
Both libre
I use gdu and never had any issues like that with it
Yeah, it helped me unblock my server where I ran out of space

















